引言
本文尝试对Navila论文进行复现,引用如下:
Paper Link
Project Link
论文解读
NaVILA: Legged Robot Vision-Language-Action Model for Navigation
基本目标
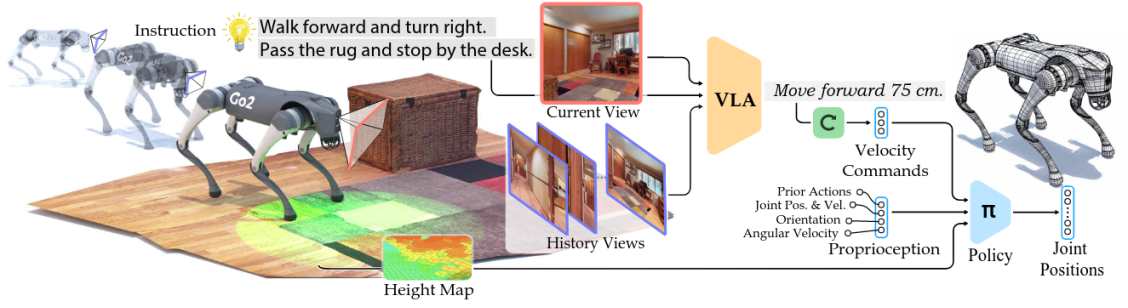
在收到人类指令后,NaVILA 使用视觉语言模型处理 RGB 视频帧,并运用运动技能在机器人上执行任务。该机器人能够成功完成长时程导航任务,并在复杂环境中安全运行。
该项目的创新基于端到端的VLA系统,该系统对通用 VLM 进行微调,以生成量化的低级动作,这个过程的推理和执行十分具有挑战性。本项目为了用更好的方式表示动作,建立了一个两级框架,将高层次的视觉语言理解与低层次的运动控制分开。
两级框架
- 高层次视觉语言理解:VLM输出语言形式的中级动作,例如“右转 30 度”。中级动作输出传达了位置和方向信息,指导机器人的导航策略。
- 低层次运动控制:训练一个低级视觉运动策略来遵循指令以对导航指令进行执行,具体来说就是将VLM的高层语言导航指令转换为精确的联合动作。
实现方法
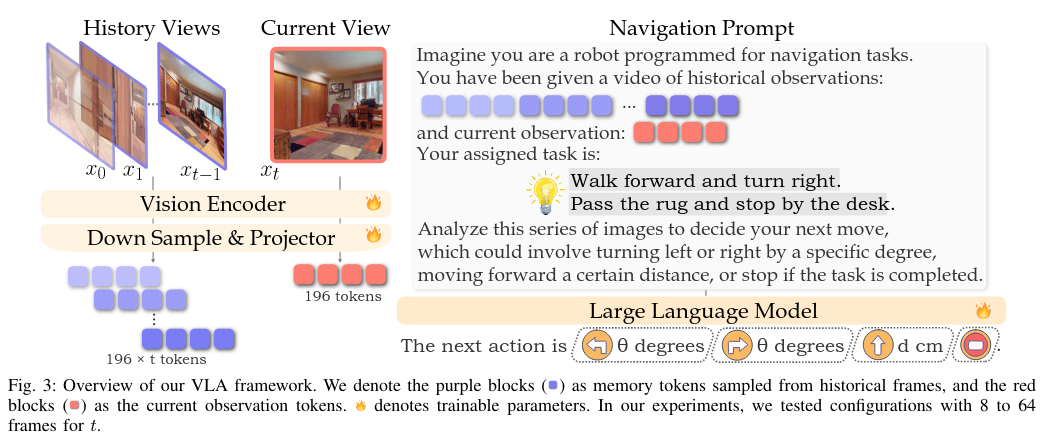
- 训练VLA用于导航
- 选择基于图像的视觉语言模型VILA
- 将历史和当前观测的标记与导航指令整合,构建导航任务提示
- 从人类视频中收集轨迹-指令对以增强在连续空间的导航能力
训练过程如下图:
- 视觉移动策略
- 该控制策略在Isaac Sim模拟器中使用Isaac Lab进行训练,然后直接部署到真实机器人上
- 将VLM输出的可执行指令转换为固定的速度指令,例如将{前进,向左转,向右转,停止}转换为{0.5 m /s,π/6 rad/s, −π/6 rad/s ,0}并执行相应时间
- 采用PPO算法训练控制策略,了解PPO算法可参考我的强化学习笔记。Critic的观察空间包含当前时间步 t 的本体感觉和速度指令,以及机器人周围的特权地形高度扫描,其中本体感觉数据包括机器人的线速度和角速度、方向、关节位置、关节速度以及之前的动作。Actor的观察空间排除了线速度,动作空间定义为期望的关节位置
- 机器人配备了一个安装在其头部底座的 LiDAR 传感器,用于检测现实中的透明物体
实验复现(评估部分)
环境配置
- 创建模型评估的虚拟环境
1
2
| conda create -n navila-eval python=3.10
conda activate navila-eval # 后续pip安装均在该环境下进行
|
- 安装 Habitat-Sim and Lab(v0.1.7),参考VLA-CE设置
由于Habitat-Sim(0.1.7)只支持python3.6~3.9,在3.10环境下需要采用源码安装
1
2
3
4
5
6
7
8
| # 安装Habitat-Lab
git clone --branch v0.1.7 https://github.com/facebookresearch/habitat-lab.git
cd habitat-lab
# installs both habitat and habitat_baselines
python -m pip install -r requirements.txt
python -m pip install -r habitat_baselines/rl/requirements.txt
python -m pip install -r habitat_baselines/rl/ddppo/requirements.txt
python setup.py develop --all
|
安装Habitat-sim(v0.1.7),参考官方源码安装指南
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| git clone https://github.com/facebookresearch/habitat-sim.git #(默认就是v0.1.7)
cd habitat-sim
git submodule update --init --recursive
git checkout v0.1.7
git submodule update --init --recursive #注意切换分支后可能导致部分submodule无效
python -m pip install -r requirements.txt
# 如果出现路径问题编译不成功,可能因为之前编译过了,进入到habitat-sim目录删除build(rm -rf build)
python -m pip install cmake
sudo apt-get update || true
sudo apt-get install -y --no-install-recommends \
libjpeg-dev libglm-dev libgl1-mesa-glx libegl1-mesa-dev mesa-utils xorg-dev freeglut3-dev
# 可能出现安装libgl1-mesa-glx不成功,可以尝试单独安装以下两个依赖
# sudo apt-get install libgl1-mesa-dev
# sudo apt-get install libegl1-mesa-dev
python -m pip install --upgrade pybind11
# 注意,编译要采用headless模式
python setup.py install --headless --cmake-args="-DCMAKE_POLICY_VERSION_MINIMUM=3.5 -DCMAKE_CXX_STANDARD=11"
|
编译时若遇到error: ‘uint16_t’ in namespace ‘std’ does not name a type; did you mean ‘wint_t’?报错,在编译时添加 cstdint 头文件:
1
| python setup.py install --headless --cmake-args="-DCMAKE_POLICY_VERSION_MINIMUM=3.5 -DCMAKE_CXX_STANDARD=11 -DCMAKE_CXX_FLAGS=-include\ cstdint"
|
解决 NumPy 兼容性问题
1
2
| cd Navila
python evaluation/scripts/habitat_sim_autofix.py # replace habitat_sim/utils/common.py
|
- 安装VLN-CE依赖
1
| python -m pip install -r evaluation/requirements.txt
|
- 安装VILA依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| # 安装 FlashAttention2
python -m pip install https://github.com/Dao-AILab/flash-attention/releases/download/v2.5.8/flash_attn-2.5.8+cu122torch2.3cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
# 安装 VILA (假设在项目根目录下)
python -m pip install -e .
python -m pip install -e ".[train]"
python -m pip install -e ".[eval]"
# 安装 HF 的 Transformers
python -m pip install git+https://github.com/huggingface/transformers@v4.37.2
# 替换部分包以兼容
site_pkg_path=$(python -c 'import site; print(site.getsitepackages()[0])')
cp -rv ./llava/train/transformers_replace/* $site_pkg_path/transformers/
cp -rv ./llava/train/deepspeed_replace/* $site_pkg_path/deepspeed/
|
5.修复 WebDataset 版本以实现 VLN-CE 兼容性
1
| python -m pip install webdataset==0.1.103
|
数据集下载
- 参考VLA-CE下载R2R和RxR数据集,并解压到
evaluation/data路径 - 下载Matterport3D数据集,可通过官网申请获取,也可参考mp3D 数据集
数据应具备如下结构:evaluation/data
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| data/datasets
├─ RxR_VLNCE_v0
| ├─ train
| | ├─ train_guide.json.gz
| | ├─ ...
| ├─ val_unseen
| | ├─ val_unseen_guide.json.gz
| | ├─ ...
| ├─ ...
├─ R2R_VLNCE_v1-3_preprocessed
| ├─ train
| | ├─ train.json.gz
| | ├─ ...
| ├─ val_unseen
| | ├─ val_unseen.json.gz
| | ├─ ...
data/scene_datasets
├─ mp3d
| ├─ 17DRP5sb8fy
| | ├─ 17DRP5sb8fy.glb
| | ├─ ...
| ├─ ...
|
评估运行
- 下载checkpoint
从a8cheng/navila-llama3-8b-8f下载预训练模型,并解压到evaluation/models/navila-llama3-8b-8f路径下,可通过以下命令下载:
1
2
| # 安装 huggingface_hub
python -m pip install huggingface_hub
|
创建下载脚本download_huggingface.py并运行,脚本内容如下:
1
2
3
4
5
6
7
8
9
10
11
| from huggingface_hub import snapshot_download
local_dir = snapshot_download(
repo_id="a8cheng/navila-llama3-8b-8f",
local_dir="~/NaVILA/navila-llama3-8b-8f",
cache_dir="~/NaVILA/navila-llama3-8b-8f/cache", # 改成自己的项目路径
token="hf_******", # 这里填写你的 HuggingFace 访问token
endpoint="https://hf-mirror.com" # 如果需要走镜像
)
print("模型下载到本地路径:", local_dir)
|
- 在r2r上运行评估
1
2
3
4
5
6
7
8
9
10
11
| # bash scripts/eval/r2r.sh CKPT_PATH NUM_CHUNKS CHUNK_START_IDX "GPU_IDS"
# 单显卡
bash scripts/eval/r2r.sh /data/code/seu004/czd/NaVILA/navila-llama3-8b-8f 1 0 "0"
# 多显卡
bash scripts/eval/r2r.sh /data/code/seu004/czd/NaVILA/navila-llama3-8b-8f 4 0 "2,3,4,5"
# 检查所有Python评估进程
ps aux | grep "run.py.*navila"
# 停止当前评估
pkill -9 -f "run.py.*navila"
# 完成评估后汇总并查看得分
python scripts/eval_jsons.py ./eval_out/navila-llama3-8b-8f/VLN-CE-v1/val_unseen NUM_CHUNKS
|
Debug
记录项目复现过程中遇到的一些问题
- 服务器网络问题
复现该项目时还是初次使用服务器,服务器由于没有图形化界面,一些仿真没办法实时显示,且服务器访问国外的网站速度较慢,不像自己电脑那样可以直接搭梯子访问。不过可以通过让服务器端走本地代理的方式来解决:
1
2
| # 本地端口号7897,需要查看自己的clash等代理软件的端口号,填写其他参数记得删去占位符<>
ssh -vvv -N -R 7897:localhost:7897 -p <远程服务器端口号> <username>@<server_ip>
|
1
2
3
| # 只在当前终端生效,将其写入~/.bashrc文件可以永久生效,但我没有那个权限
export http_proxy="http://localhost:7897"
export https_proxy="http://localhost:7897"
|
这样服务器就可以访问外网了,克隆github项目、下载hugging_face模型等都可以顺利进行。
- Matterport3D数据集加载问题
mp3d数据及下载比较麻烦,使用官方给的脚本不知道为什么只会下载scans文件夹,这里面一般是深度、RGB图片等原始数据,评估过程其实是不需要的,真正需要的是task文件夹下的文件,但即使我使用–task habitat后缀仍然没法下载task相关文件,目前没找到解决办法,我是直接去找师兄要了数据集,也可以去咸鱼上买现成的。
最后的场景文件夹下应包括.glb等格式的文件。不同的场景有不同的ID,理论上评估预训练模型需要许多场景,但我实测先装一个ID为zsNo4HB9uLZ的场景就可以跑通评测,过程中有的episode发现没有的场景会直接跳过,后续可以慢慢补充其他场景再进行评估。
实验结果
- 运行r2r.sh脚本后,终端会实时可视化VLM的action指令
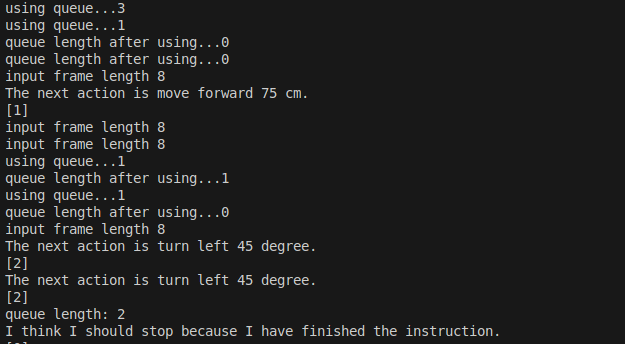
- 并会在
valuation/eval_out/navila-llama3-8b-8f/VLN-CE-v1/val_unseen/videos路径下生成大量评估视频,视频左下方为导航指令,视频名称中的spl是导航中常用的评估指标,基准值为1/0代表是否成功,再乘上一个最短路径与实际路径比值。
每个视频是一个episode,会选取一个场景进行评估,解压R2R数据集下的val_unseen.json.gz文件后可以看到episodes总共有1838个,8张显卡大概要跑2~3小时,如果不查看最终分数的话不跑完也可以。 - 其中一个 spl=1 的episode如下: