VLM
LLaVA
一、训练流程
原项目的readme提供了llava训练流程的概览,主要包括两个阶段:
- 第一阶段:预训练(特征对齐)
这一阶段的目标是将图像特征映射到语言维度,使得模型能够理解视觉信息,核心任务是训练一个 vision-language connector.。- 数据集:图像-文本对
- 脚本:/scripts/v1_5/pretrain.sh
脚本中有一行参数--tune_mm_mlp_adapter True,对应训练脚本train.py中的代码: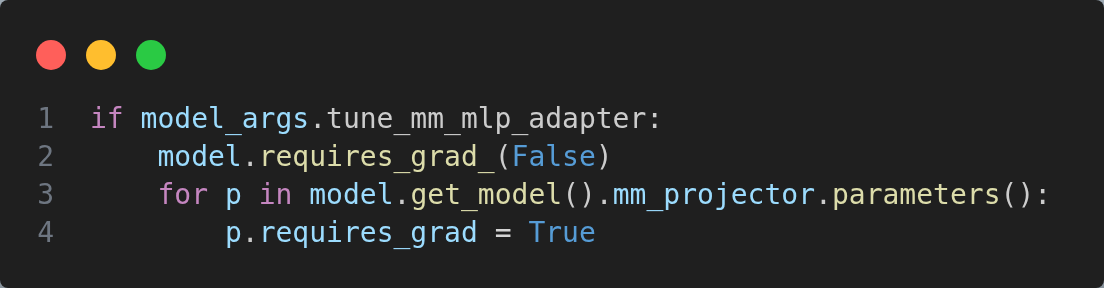 表示只训练
表示只训练mm_projector的参数,其他参数全部冻结。mm_projector就是将图像映射到语言维度的connector,用来进行特征对齐,原文描述是一个两层的MLP。
- 第二阶段:视觉指令微调
这一阶段的目标是让模型能够根据视觉输入执行指令,进行多模态理解和生成,核心任务是端到端地微调 LLM 和 connector。- 数据集:包括指令对话数据(json文件)和图像
- 脚本:/scripts/v1_5/finetune_lora.sh
二、prepare_inputs_labels_for_multimodal() 函数解读
源代码
该函数用于将输入文本和图像进行拼接,并生成对应的标签,是视觉语言融合的核心函数,
事例如下:
- 首先对原始文本进行分词
| |
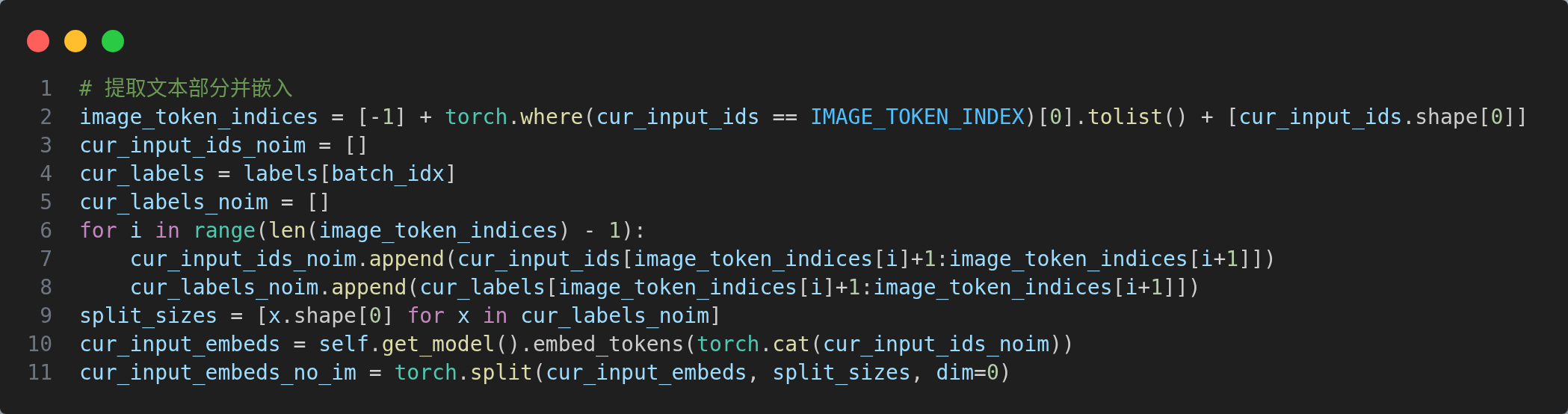
- 提取文本并嵌入
| |
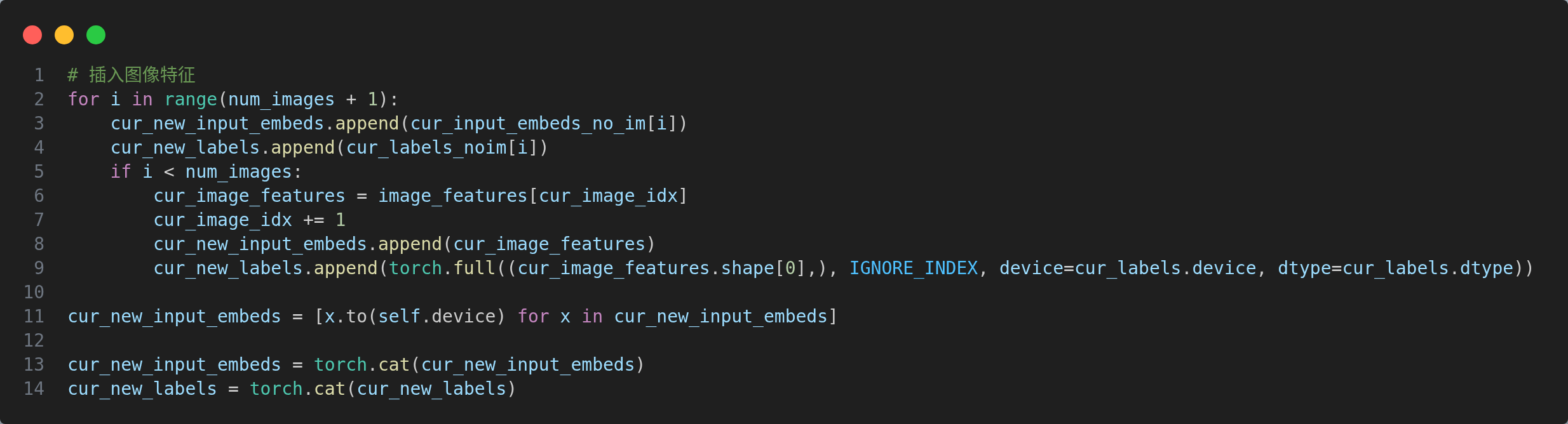
- 插入图像特征
| |
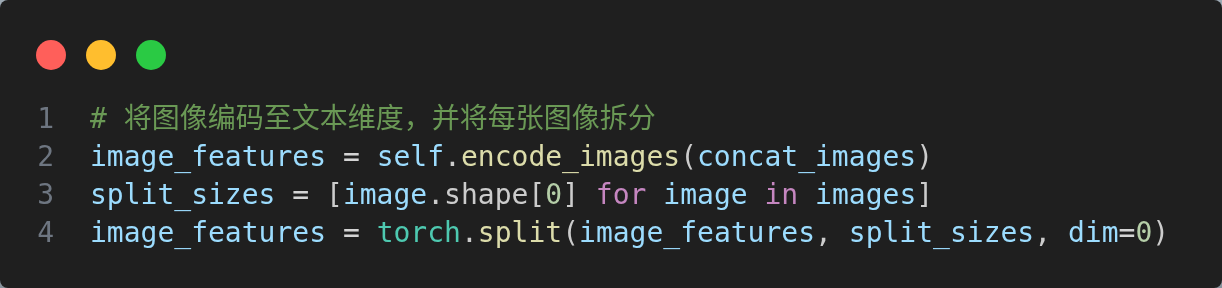
图像特征获取如下:
- 插入图像特征后的序列被送入LLM进行处理,具体见llava_llama.py中的
forward()函数。
三、lora微调
使用scripts/v1_5/finetune_lora.sh脚本进行微调,可以看到 lora 参数如下:
| |
- lora_enable:启用lora微调
- lora_r:lora秩,控制低秩矩阵的维度
- lora_alpha:lora缩放因子,控制lora更新的幅度
- mm_projector_lr:多模态投影器的学习率
配置LoRA参数并添加到模型
 其中
其中get_peft_model()函数把 LoRA 注入到目标层,返回一个 PEFT 包装后的模型,之后训练时只更新 LoRA 参数,基础模型权重保持冻结,具体可参考PEFT文档 。注意:原项目中的pyproject.toml文件中没有指定peft库的版本,安装时会默认安装最新版本,实测目前peft最新版本与项目指定的transformers库存在兼容性问题,建议使用peft 0.4.0版本 。
VLA
OpenVLA
class ActionTokenizer类解读
源代码
将连续动作区间均匀离散化
bins: $\underbrace{[-1.0, …, 1.0]}_{256个边界点}$
$\downarrow 取区间中心 $
bin_centers: $\underbrace{[-0.99609375, …, 0.9960784]}_{255个中心点}$
| |
- 动作编码
action $\xrightarrow{clip}$ action $\in [-1.0, 1.0] \xrightarrow{digitize}$ discretized_action $\in [1, 256]$ $\xrightarrow{decode}$ token_id
| |
- 动作解码
token_id $\xrightarrow{decode}$ discretized_action $\in [1, 256] \xrightarrow{clip}$ decretized_action $\in [0, 254]$ $\xrightarrow{取值}$ bin_centers[discretized_actions]
| |